
Cpp瞎写
鉴于写博客有助于自己的学习,于是博主将自己所学的c++总结了一下
总体知识
总述
基础知识分为: 变量类型–>基础语法–>函数–>类–>库(细说stl)–>多线程(进程)–>堆栈–>模板
工程目录
我的工程目录–>有助于分类
1 | Projects/Project_1 |
另外: 头文件放结构体, 宏定义, 函数声明,类声明, 全局变量…而源文件放函数原型, 类原型.
Thinking: 可以把库底层写成xxx_Base.cpp, 把调用接口写成xxx_API.cpp
静态库的创建
1 | g++ -c 1.cpp 2.cpp 3.cpp |
动态库的创建
1 | // PIC -> Position Independence Code |
- Tips: 使用g++创建动态库时, 一定要在函数的外部加上
extern "C"{函数}, 否则会出现函数符号无法找到.
例:
1 | // mylib.c |
g++的使用
g++ main.cpp 1.cpp 2.cpp -o main.exe
| 选项 | 作用 |
|---|---|
-o |
指定输出文件名 |
-std=c++17 |
指定标准版本 |
-g |
生成调试信息 |
-O0/-O1/-O2/-O3 |
优化级别 |
-Wall |
生成所有警告信息 |
-S |
生成汇编.s文件 |
-c |
生成.o文件 |
-E |
生成预处理.i文件 |
-I/path/to/include |
头文件路径 |
-L/path/to/lib/ |
库路径 |
-lmylib |
链接libmylib.a静态库/libmylib.so(dll)的动态库(对库的引用放在命令的结尾) |
-DDEBUG |
相当于添加#define DEBUG |
变量类型
区分数据类型的唯一标准是内存的字节占用,所有的数据都是二进制(01)表示的,不同的数据类型是编译器把二进制数据跟人进行交流的"桥".
- 初识变量
| 名称 | 符号 | 占用字节 |
|---|---|---|
| 字符 | char | 1 |
| 布尔值 | bool | 1 |
| 短整型 | short | 2 |
| 整型 | int | 4 |
| 长整型 | long | 8 |
| 单精度浮点数 | float | 4 |
| 双精度浮点数 | double | 8 |
| 指针 | 类型* | 4(32位系统)/8(64位系统) |
| 联合体 | union | 与最大的数据类型一样大 |
| 枚举体 | enum | 1/2/4(通常) |
| 结构体 | struct | 有内存补齐操作无法确定 |
字符
'x'使用''包裹的一个字符<–man ascii可以在线查看ascii表
整数
- 有符号整数: 最高位0表示正数,1表示负数
假如int类型来解释100…100,该值为 - 无符号整数:
浮点数
遵循IEEE 754 标准
- float(32)
| 部分 | 符号位 | 指数位 | 尾数位 |
|---|---|---|---|
| 位数 | 1 | 8 | 23 |
- double(64)
| 部分 | 符号位 | 指数位 | 尾数位 |
|---|---|---|---|
| 位数 | 1 | 11 | 52 |
规格化值(Exp不全为0或1)
解释:
- sign(符号位): 0代表正,1代表负数
- Exp(指数位): 实际指数为(Exp - 127(float)/1023(double)),范围是(-126 ~ 127)/(-1022~1023)
- Man(尾数位):
非规格化值:
- Exp全为0时: 0值
- Exp全为1,尾数全为0时: 无穷大
- Exp全为1,尾数不全为0时: NaN
数组
须知:
- 数组里可以装任何数据类型
- 数组实际上是在栈上的一连串的内存,数组名代表这一连串地址的起始地址(小地址<–栈向低地址增长)
- 数组名不能更改(
arr+2) - 字符串(字符组成的数组,结尾是0(不是’0’))
- 数组的长度必须在编译前就知道(不能用变量,而必须用常量const)
- 指针的加减数字是根据指针指向的数据类型而定的,如
(int*)p + 1是地址加4(int是4个长度)
- 性能优化:
将多维数组写成一维数组(防止内存碎片)
1 | int a2d = new int[5*5]; |
结构体
- 用处: 处理多返回值的函数
1 | struct source |
- 与类的区别: 结构体默认public, 类默认private
Tips: 我们当然学习类啦
指针
注意
- 指针需要初始化
int* ptr = nullptr(推荐使用nullptr()而非0或者NULL) - 通过new创建的(堆)内存块被释放后要将指向内存块的指针赋nullptr防止指针悬空,栈上的指针自动释放
优点
- 通过指针可以不用复制大量内存来传递参数,而是可以直接传递指针优化性能
智能指针
#include <memory>
| 名称 | 介绍 |
|---|---|
std::unique_ptr<类型> |
超出作用域自动释放,无法复制,只能移动std::unique<int> p2 = std::move(p1) |
std::shared_ptr<类型> |
计数为0自动释放,可以复制 |
std::weak_ptr<类型> |
lock()可以转化为shared_ptr来观察值,解决shared_ptr循环引用导致的计数无法归零 |
枚举体
1 | enum COLORS : char{ // 指定枚举体基础类型是char |
enum中的例子会隐式转化,enum class不会隐式转换,从而可以在不同的enum使用同名的名字
结构体
内存对齐规则
从第一个开始遇到的最大的哪个数据类型为基础,之后的每个数据的起始位置必须是目前为止最大的数据的整数倍
1 | struct TestStruct { |
结构体大小是0->2->4->8,大小是8bytes
联合体
须知:
- 联合体中的所有成员共享同一块内存空间。联合体的大小等于其最大成员的大小,利用类型双关.
1 | union Price{ |
函数
函数说明符
1 | void f() noexcept; // 函数 f 不会抛出异常 |
函数指针
返回类型 (*指针变量名)(参数类型列表);
举例
1 | int add(int a, int b){ |
更灵活的方式
1 |
|
lambda函数
格式
1 | auto f = [](int a, float b) |
函数重载
在 C++ 中.如果两个函数名相同.但参数列表(个数、类型或顺序)不同.它们是不同的函数.这是通过函数重载实现的
1 | void log(int x) |
类
类是用户自定义的数据类型.包含数据成员(属性)和成员函数(方法)
基本结构
1 | class ClassName { |
类的可见性
| 关键字 | 可允许访问的范围 |
|---|---|
| private | 这个类和友类 |
| protected | 这个类及子类及友类 |
| public | All |
类的特殊函数
构造函数
ClassName(int val, int dot) : data(val),data2(dot) {} // 初始化列表—data,data2的顺序要和声明的一样ClassName a(1,2);—利用值构造类
析构函数
~ClassName() { /* 清理资源 */ }
拷贝构造函数
ClassName(const ClassName& other);ClassName b = a—利用类构造类
拷贝赋值函数
ClassName& operator=(const ClassName& other);c = a—类给类赋值
移动构造函数
ClassName(ClassName&& other) noexcept;ClassName d = std::move(a)—利用类构造类
移动赋值函数
ClassName& operator=(ClassName&& other) noexcept;e = std::move(a)—类给类赋值
单例
删除赋值构造函数,private构造函数
1 | class Singleton |
类的其他特征
类的static数据
为类的属性而非实例,所有该类的实例共享这一份数据
static int val;
类的static函数
static方法只能访问static数据
static void printCount() { cout << count; }
友元函数
friend void friendFunction(ClassName obj);
友元类的声明
friend class ClassName
运算符重载
1 | ClassName operator+(const ClassName& other) { |
继承
class Derived : public Base { /* ... */ };
多态
虚函数存在于父类,目的是为子类提供函数模板.重写函数存在子类,为子类提供不同的函数
虚函数
virtual void method() { /* 基类实现 */ }
纯虚函数
Tips: 包含纯虚函数的类无法实例化
virtual void pureMethod() = 0;
举例
1 | class printable |
虚析构函数
当基类的析构函数是虚函数时.通过基类指针删除派生类对象时.会正确调用派生类的析构函数。如果基类的析构函数不是虚函数.则只会调用基类的析构函数.导致派生类的资源泄漏。
1 | Base *poly = new Diversy(); //Base是父类, Diversy是派生类 |
类的高级特征
override
void mtthod override;
final
class ClassName final{};禁止继承
成员初始化列表
ClassName a{1,2};
this
this代指本实例的指针
语法
运算符
算术运算符
- [ ] +
- [ ] -
- [ ] *
- [ ] /
- [ ] %
- [ ] ++ # 注意前后置的区别
- [ ] –
关系运算符
- [ ] ==
- [ ] !=
- [ ] >
- [ ] <
- [ ] >=
- [ ] <=
逻辑运算符
- [ ] &&
- [ ] ||
- [ ] ! # 不全为0则为1
位运算符
- [ ] &
- [ ] |
- [ ] ^ # a^b==0 --> a==b
- [ ] ~ # 按位取反
- [ ] << # 一般有符号是算术左移符号逻辑左移
- [ ] >>
赋值运算符
- [ ] =
- [ ] +=
- [ ] -=
- [ ] *=
- [ ] /*
- [ ] %=
- [ ] <<=
- [ ] >>=
- [ ] &=
- [ ] ^=
- [ ] |=
其他运算符
- [ ] sizeof
- [ ] condtion?x:y
- [ ] ,
- [ ] .
- [ ] ->
- [ ] cast # int(2.2)
- [ ] & # 取地址
- [ ] * # 取值
条件分支和循环
条件分支
if
if else
if else if
switch case
1 | switch(var){ //var是整型或enum |
循环
while
do…while
for
关键词
- continue
- break
- return
Tips: 进入循环时最好将结果存储在循环体外的变量,减少内存访问
修饰符
访问控制修饰符
| public | 类内外均可 |
|---|---|
| private | 类内,友元类可以访问 |
| protected | 类内,友元类和子类可以访问 |
存储类修饰符
static
- 局部: 只初始化一次
- 全局/函数: 作用域限定在本文件
- 类成员: 所有实例共享这个数据
extern
- 声明变量/函数已经在其他文件被定义了
mutable
- 可以在
const成员函数中修改类的成员
eg:
1 | class xx{ |
thread_local
详见此处
1 |
|
类型限定符
const
- const 变量 --> 常量
- 成员函数 const -->禁止修改成员状态
- const int* 指针指向常量;int *const 指针不可变
volatile
- 变量可能被外部修改,禁止编译器优化
类型修饰符
signed/unsigned
short/long/long long
函数修饰符
inline
- 内联函数, 直接将函数体的源代码复制到调用处(适用于函数体小的函数)
vitural
- 定义虚函数
override
- 重写虚函数
final
- 禁止派生类覆盖虚函数, 或者禁止子类
constexpr
- 编译时可求出函数的返回值
noexcept
- 函数不可抛出异常
explict
- 禁止构造函数隐式转换
输入输出
cin
- cin >> data; // 忽略前导空格,到下一个空白符或换行符或EOF停止读入
- cin.getline(); // 丢弃换行符
- cin.get(); // 逐个字符读取,不会丢弃空格和换行符
文件
1 |
|
堆和栈
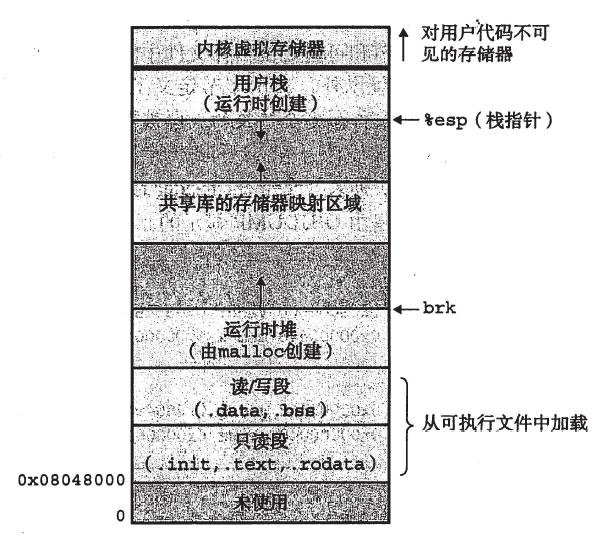
- 栈(Stack)
特点
-
内存分配方式:由编译器自动分配和释放,遵循“后进先出”(LIFO)原则。
-
存储内容:局部变量、函数参数、函数调用信息(如返回地址)等。
-
内存管理:内存分配和释放由系统自动完成.效率高。
-
大小限制:栈的大小通常较小(如几MB)具体取决于操作系统和编译器设置。
-
访问速度:访问速度快.因为内存分配是连续的。
-
栈向下增长
优点
-
高效:内存分配和释放由系统自动完成。
-
简单:无需手动管理内存。
缺点
-
大小受限:栈空间有限.不适合存储大量数据。
-
生命周期固定:变量的生命周期仅限于函数作用域。
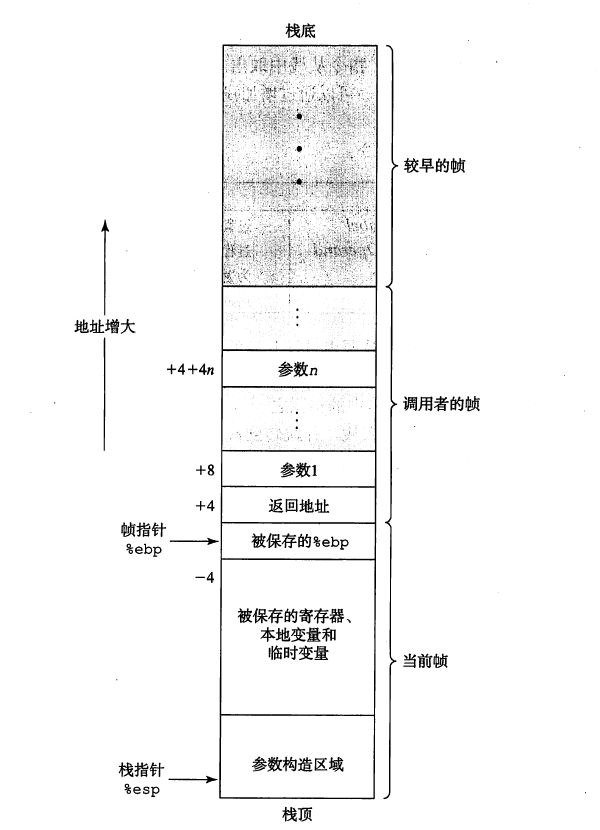
栈帧结构
- 堆(Heap)
特点
-
内存分配方式:手动分配和释放(new/delete或者智能指针)。
-
存储内容:存储动态分配的内存(如对象、数组等)。
-
内存管理:需要程序员手动管理.否则可能导致内存泄漏或野指针。
-
大小限制:堆的大小通常较大.受系统可用内存限制。
-
访问速度:访问速度较慢.因为内存分配是动态且不连续的。
-
堆大体上向上增长(但是内存不是连续分配的)
-
假设堆的起始地址为 0x1000,当程序需要分配一块 100 字节的内存时,操作系统可能会分配地址范围为 0x1000 到 0x1064 的内存块。如果程序再次需要分配内存,新分配的内存块的地址将会大于 0x1064。
元编程模板
template
1 | template <typename T, int N> |
泛型设计的理想状态是一个查找算法将可以作用于数组,联表,树,图等各种数据结构之上,变成一个通用的,泛型的算法。
STL(Standard Template Library)
#include <bits/stdc++.h>
总览
- [ ] 基础知识
- [ ] 算法(Algorithm)
- [ ] 容器(Container)
- [ ] 迭代器(Iterator)
- [ ] 仿函数(Function Object)
基础知识
类型转换
1 | float f = 3.14; |
容器
pair
1 | pair<int, pair<int, int>> p = {1, {3,4}}; // 初始化 |
vector
特征: 自由伸缩(对性能有影响), 存储在堆上
1 | // init |
list
特征: 可以双向插入
1 | // init |
stack
特征: 单向操作,LIFO(后进先出)
1 | //init |
queue
特征: 单向操作. FIFO(先进先出)
1 | // init |
priority_queue
特征:最大值在顶部,其余像queue
1 | // init |
set
特征: 按大小排序记录唯一性元素
时间复杂度: O(lgn)
1 | // init |
multiset
特征: 按大小排序记录元素
1 | // init |
unorder_set
特征: 无序记录唯一性元素
1 | // init |
map
特征 : 以键的大小顺序排序,类似字典(但是字典的类型是任意的)
1 | // init |
multimap
特征: 类似map(但是可以存储多个键)
unordered_map
特征: 不会按照键的大小排序
算法
sort
快速排序
sort(it_begin, it_end(), cmp)
默认是升序,
greater<int>是降序
cmp返回结果为真, 上一个元素在前(即排序正确不需要重排)
__builtin_popcount
- 计算二进制位数
1 | int bits = __builtin_popcout(int x); |
next_permutation
1 | string s = "123" |
max_element
1 | int maxi = *max_element(it_begin, it_end); |
reverse
reverse(arr.begin(), arr.end()反转元素
gcd/lcm
gcd(int a, int b)最大公倍数
lcm(int a, int b)最小公因数
向上取整, 向下取整
a/b --> floor
a/b + 1 --> ceil
快速幂
利用位运算
1 | int quickpow(int a, int b) |
 alipay
alipay



